MACHINE LEARNING W ZARZĄDZANIU ZAPASAMI
Technologia uczenia maszynowego automatyzuje i standaryzuje proces prognozowania oraz pozwala zoptymalizować cały łańcuch dostaw. Jak poprowadzić proces, by uzyskać najlepszą możliwą prognozę na podstawie firmowych danych i wiedzy o procesie biznesowym?
Adam Karolewski
Koncepcje uczenia maszynowego (machine learning) są coraz popularniejsze w świecie biznesu. Przedsiębiorcy chętnie się chwalą wdrożeniami takich rozwiązań w swoich organizacjach. Włączenie ich do procesów biznesowych świadczy o wysokich kompetencjach kadry kierowniczej, a finalnie o konkurencyjności oferty. Ale czym właściwie jest owo uczenie maszynowe i sztuczna inteligencja w przedsiębiorstwie? I co najważniejsze: czy faktycznie przynosi realne korzyści branży retail?
Odpowiedzi na te pytania dobrze ilustruje przykład wykorzystania machine learning do zarządzania zapasami w sklepach. Technologia ta automatyzuje i standaryzuje cały proces prognozowania. Umożliwia przeliczenie tysięcy, a nawet milionów produkto-lokalizacji, co wcześniej nie było realne. Częsta aktualizacja prognoz i przeliczanie z uwzględnieniem pojawiających się informacji dodatkowo poprawia jakość prognozowania.
Wysokiej jakości prognozy mają tu ogromne znaczenie, ponieważ wiele produktów ma stosunkowo krótkie czasy dostaw w obrębie sieci dystrybucji. Powstanie nadmiernych zapasów w którymkolwiek ogniwie łańcucha jest kłopotliwe. Dzięki automatyzacji procesów zarządzania zapasami i zamówieniami od dostawców oraz w łańcuchu dystrybucji pomiędzy ogniwami można szybko i elastycznie reagować na zmiany popytu i zapasu.
Na czym polega zarządzanie zapasami?
Zarządzanie zapasami składa się z dwóch głównych etapów: prognozowania popytu, a następnie wyliczania zapotrzebowania i zarządzania zasobami. To właśnie w fazie prognozowania możemy wykorzystać uczenie maszynowe – służy ono do uzyskania najlepszych możliwych prognoz przyszłego popytu. Dzięki temu możemy lepiej zaplanować zapasy: uniknąć zarówno braków, jak i nadmiaru.
Wszystkie metody zarządzania zapasami bazują na założeniu o znajomości popytu. W tym miejscu wykorzystujemy nasze prognozy, a także błędy prognoz. Mamy kilka podstawowych metod zarządzania zapasami, m.in.: min. – max., przegląd okresowy (periodic review), stała wielkość zamówienia / stały punkt zamawiania / ciągły przegląd – reorder point, stały punkt zamawiania z rozszerzeniem o zapas informacyjny.
Metody te mają XX-wieczny rodowód i wiążą się z uproszczeniami wynikającymi z ograniczeń przeliczeniowych. Dzięki komputeryzacji, dużej wydajności obliczeniowej i technikom programistycznym możemy natomiast budować złożone procesy sterowania zapasami.
Jednak samo prognozowanie, nawet najlepsze, nie ma znaczenia, jeżeli nie stanowi integralnej części procesów biznesowych firmy. Sprzęgnięcie procesu prognozowania w oparciu o ML i przedłużenie tego procesu o kontrolę zapasów i zgłaszanie zapotrzebowania (generowania zamówień) daje wielką korzyść na poziomie operacyjnym. W branży retail taka automatyzacja jest wysoce pożądana. Setki czy tysiące operacji wysyłek produktów do punktów sprzedaży każdego dnia mogą być wsparte precyzyjnym procesem, zautomatyzowanym, który podoła dowolnej skali.
Z kolei osoby zaangażowane dotychczas w ręczne przeliczanie tysięcy produktów i poprawę pojedynczych prognoz mogą zaangażować się w poprawianie całego procesu. Są w stanie poświęcić więcej uwagi nowym produktom, okresom promocyjnym lub planowaniu zmian cen.
Planowanie zapasów z wykorzystaniem machine learning
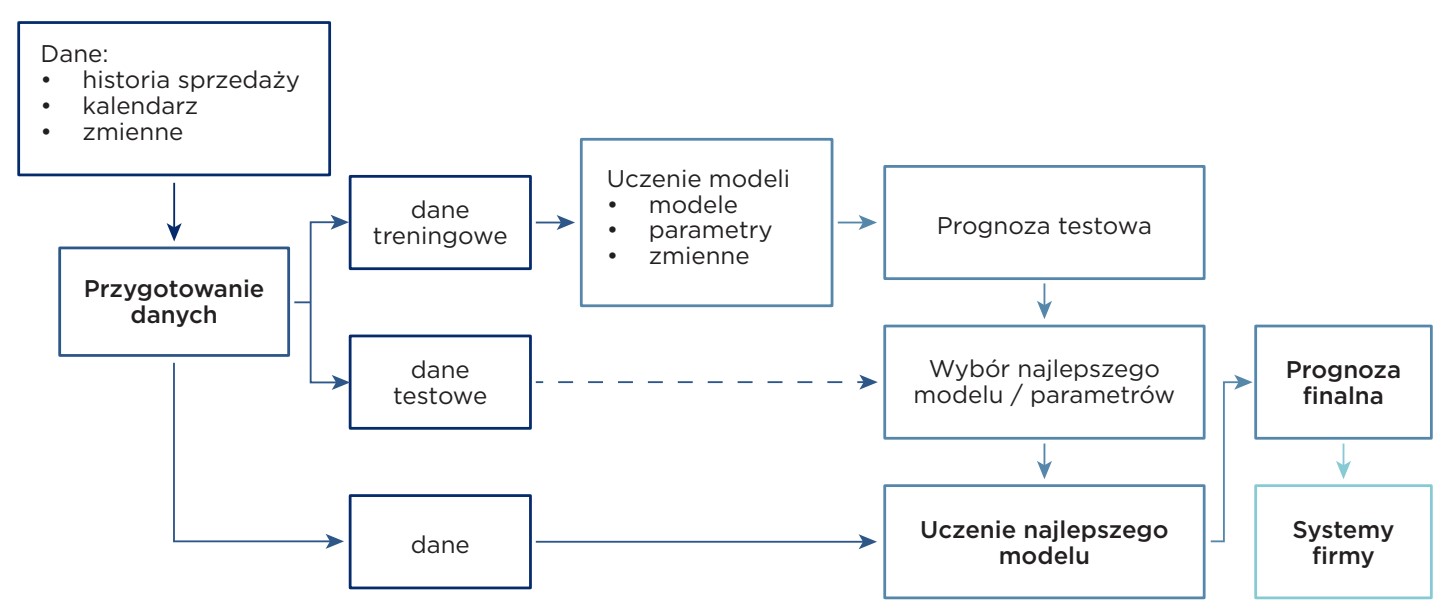
Przykładowy proces prognozowania zapotrzebowania na produkt z wykorzystaniem ML zaczyna się od załadowania wybranych danych opisujących popyt na niego. Można skorzystać z historycznych danych dotyczących sprzedaży, pod warunkiem, że dobrze opisują popyt. Warto je urealnić, np. Odfiltrowując sprzedaż przy braku lub niepełnym stanie magazynowym. Jeśli znamy lub podejrzewamy relacje przyczynowo-skutkowe między ilością sprzedaży a naszymi działaniami (np. zmiany ceny, promocje), okresami świątecznymi, nieprzewidywalnymi zdarzeniami czy sezonowością, to takie dane również warto uwzględnić. W ten sposób otrzymujemy zmienne, które wspomogą nasz model prognozowania popytu.
Wspomniane wyżej dane pochodzą z różnych źródeł i zapewne są w różnych formatach. Należy je zebrać w jednym miejscu i doprowadzić do matematycznej postaci, którą akceptuje model. Następnie przygotowane dane przepuszczamy przez algorytmy, wykorzystując do tego celu próbną (testową) prognozę bazującą na historycznych danych. Dzięki temu otrzymujemy realistyczne wyniki. Na ich podstawie wybieramy następnie:
- – najlepsze modele (jeśli używamy ich kilku),
- – najlepsze parametry modeli, procesu i jego konfiguracji,
- – wybieramy najskuteczniejsze zmienne.
Prognoza finalna jest tworzona na podstawie najlepszego modelu, parametrów lub zmiennych. Tak poprowadzony proces daje dużą gwarancję, że otrzymamy najlepszą możliwą prognozę bazującą na firmowych danych i wiedzy o procesie biznesowym.
Machine learning wspiera dystrybucję i sprzedaż
Machine learning można wykorzystać także do organizacji łańcucha dostaw, choć architektura prognozowania zależy nie tylko od danych, ale i od struktury samego łańcucha dostaw, a także stopnia integracji z dostawcami i klientami. Każde miejsce, z którego następuje dystrybucja – magazyn centralny lub dystrybucyjny, punkt dystrybucji dla klienta końcowego – powinno mieć swoją własną prognozę popytu, najlepiej bazującą na ML. Dzięki temu można uniknąć wielu efektów wtórnych, które w łańcuchu dostaw zamieniają się w efekt byczego bicza. Dzieje się tak, jeśli magazyn prognozuje swoje wolumeny w oparciu o zlecenia zapotrzebowania (np. od hurtowni), a nie o popyt rzeczywisty. Minima logistyczne czy inne działania związane z tworzeniem zapasów mogą zniekształcić informacje o faktycznym popycie i taka informacja spłynie w głąb łańcucha dostaw, tworząc nieprawdziwy obraz popytu. Dodatkowo w takiej sytuacji do prognozy popytu przechodzi część informacji o zapasie bezpieczeństwa i odbiera nam kontrolę nad tym zapasem.
Innym wyzwaniem w retail, w którym machine learning wspiera sprzedaż, jest omnichannel, czyli obsługa za pomocą sprzedaży stacjonarnej i e-commerce. W sprzedaży wielokanałowej mogą występować oddzielne warunki sprzedaży (np. promocje), zachowanie klientów mogą określać inne zmienne, a same zmienne mogą przyjmować inne wartości. Dzięki machine learning kanały mogą mieć oddzielne procesy prognostyczne, a jednocześnie korzystać z tego samego zapasu dla tych samych produktów, we wspólnym magazynie. Oczywiście wprowadza to dodatkowy narzut organizacji pracy i przestrzeni, ale jedno jest pewne: nie będzie to proces niekontrolowany.
Jeszcze większym wyzwaniem jest wymiana informacji prognostycznych z dostawcami oraz wspólne prognozowanie i zarządzanie łącznym zapasem. Oznacza to dzielenie się informacjami, które są ważne z punktu widzenia danej organizacji i mogą być wrażliwe lub poufne, ale jednocześnie przynosi wiele korzyści. Równoważą one lub przewyższają koszty dzięki lepszej koordynacji, brakowi przykrych niespodzianek przy planowaniu sprzedaży i produkcji. Pozwalają także obniżyć łączny poziom zapasu, a także koszty transportu i obsługi zamówień.
Machine learning i standardy GS1
Zarządzanie łańcuchem dostaw (SCM) jest dziedziną opartą na tradycyjnym modelu zarządzania bezpośredniego. Ten obszar działalności gospodarczej nie czerpie w kluczowych obszarach z korzyści, jakie daje cyfryzacja. Teoria zarządzania zapasami jeszcze nie zaadaptowała osiągnięć uczenia maszynowego i nie zsyntetyzowała ich w postaci nowej teorii. Ale to się zmienia m.in. za sprawą czytników kodów kreskowych.
Powszechność kodów kreskowych w formacie numerów GTIN (wcześniej kodów EAN) pozwala jednoznacznie identyfikować dany produkt w całym łańcuchu dostaw, szczególnie pomiędzy oddzielnymi organizacjami. Zazwyczaj firmy posiadają własne, wewnętrzne oznaczenia produktów i tylko kody kreskowe pozwalają na jednoznaczną identyfikację tych samych produktów bez wymiany danych z Master Data. Skraca to przygotowanie procesów integracyjnych i eliminuje potencjalne błędy oraz nieporozumienia.
Jednak wdrożenie rozwiązań klasy ML do zarządzania łańcuchami dostaw stawia nowe wymagania organizacji, która chciałaby z nich skorzystać. Potrzebne są odpowiednie kompetencje pracowników, a sama organizacja musi być przygotowana do zarządzania za pomocą danych (data- -driven), przede wszystkim odnośnie do kultury pracy bazującej na procesach biznesowych wykorzystujących machine learning.
Wdrożenie technologii ML może zająć od roku do pięciu lat, choć pierwsze prototypy można zbudować w ciągu 1 miesiąca. Takie rozwiązania można tworzyć samodzielnie lub kupić od dostawców (np. jako usługę w modelu SaaS). Ta druga opcja, choć nie zawsze skrojona na miarę firmowych procesów, pozwoli szybko wejść w dziedzinę machine learning i poznawać ją oraz stosować coraz lepiej.